1. Introduction
Building robust and accurate models for production-ready applications is not just about training the models, however understanding the data, cleaning it and restructuring it to match the model framework requirements. In medical imaging, this challenge is particularly pronounced due to the complexity and variability of clinical data. Medical images often come with a host of issues including inconsistent formats, varying resolutions, annotation errors, and privacy concerns. These issues can significantly hinder model performance if not properly addressed during the preprocessing stage.
This blog post walks through the complete journey of preparing the TBX11K tuberculosis detection dataset for xxx training, including the data exploration, preprocessing and format conversion steps taken.
2. Dataset
The TBX11K dataset is a large-scale collection of chest X-ray images annotated with bounding boxes for tuberculosis (TB) detection and localization. It's designed for multiple computer vision tasks:
- Object Detection - locating TB regions in X-rays.
- Image Classification - determing TB presence
2.2 Initial Data Analysis
2.2.1 Dataset Composition
First step is understanding the dataset. The TBX11K dataset is structured as follows:
- Training set: 6 888 images with 902 annotations
- Validation set: 2 088 images with 309 annotations
- Testing set: 3 302 images with no labels
2.2.2 Catergory Analysis
The dataset contains annotations for 3 types of TB manifestations:
- ActiveTuberculosis
- ObsoletePulmonaryTuberculosis
- PulmonaryTuberculosis
After further analyzing the annotations, the following was discovered:
- Training set:
- ActiveTuberculosis: 724 instances
- ObsoletePulmonaryTuberculosis: 178 annotations
- PulmonaryTuberculosis: 0 annotations
- Validation set:
- ActiveTuberculosis: 248 instances
- ObsoletePulmonaryTuberculosis: 61 annotations
- PulmonaryTuberculosis: 0 annotations
2.2.3 Class Imbalance
Another insight emerged from this distribution, as shown below. ActiveTuberculosis cases outnumber ObsoletePulmonaryTuberculosis by roughly 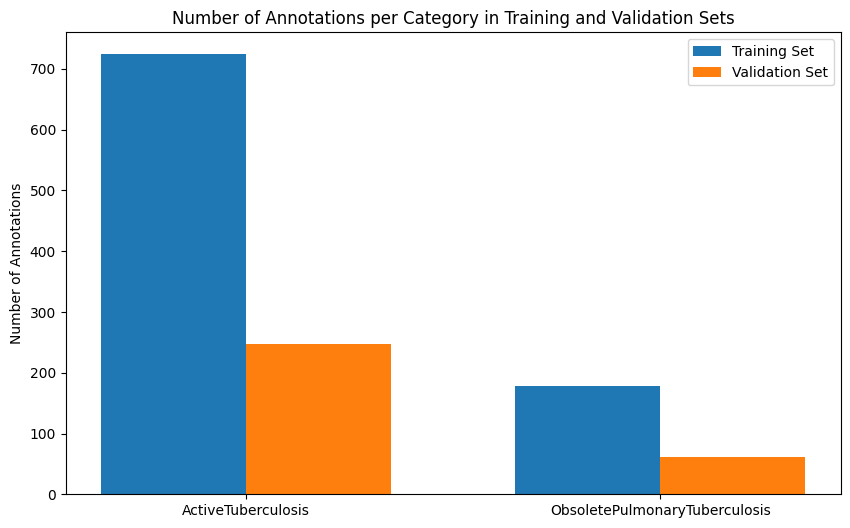
To mitigate this, some of the solutions considered include:
- Data-Level Solutions - manipulating the training data quantity and diversity through techniques such as oversampling, undersampling and data augmentations.
- Algorithm-Level Solutions - adjusting how the model learns from the existing data through loss and feature re-alignment methods.
3. Preprocessing Pipeline
3.1 Removing Unannotaed Images
The first preprocessing step was to clean the COCO JSON annotation files by removing image entries that have no corresponding annotations. These images don't contribute to learning for object detection task, they also accumulate unnecessary disk space and increase training time. This was accomplished by parsing the COCO JSON files into a cleaning function that identifys images without annotations and generating new JSON files that only include images with at least one bounding box annotation.
- Training set: 6 888 images → 599 images (91% reduction) .
- Validation set: 2 088 images → 257 images (88% reduction).
- Testing set: 3 302 images (no change, as no annotations provided).
3.2 Removing Extra Class
Next, the empty class "PulmonaryTuberculosis" was removed from the annotation files. This involved updating the category definitions for the training and validation datasets. Removing the unused class, reduced complexity in the dataset and ensured that the model focuses on learning from relevant categories only.
6. Conclusion
This blog has presented a guided approach to addressing the data quality challenges inherent in medical image object detection. By implementing structured preprocessing workflows.
Further information on models trained, demostrating the effectiveness of these approaches will be shared soon...